
How I ended up running a worldwide protein design competition
The origin story of the BioML Society

One question I’ve been asked a few times when presenting the Bits to Binders competition is how I got started running it. The short answer is that I never intended to start this project at all: it just sort of happened. The longer, more correct answer requires me to tell the origin story of the BioML Society.
In 2022, I started my PhD at the University of Texas. Early on, I met Aaron Feller, who had also just started his PhD and wanted to get into researching deep learning for biology. After working together for a bit, we wanted to find other people who were interested in this problem, so we decided to start a group for machine learning and biology. ChatGPT had just come out, and we thought it would be fitting to have it come up with names for our group, and with it we landed on “The BioML Society”. We created a logo with MidJourney and a simple Squarespace website with AI-generated boilerplate text, then advertised it across campus, of course using ChatGPT to help write the blurbs.
We held our first meeting in early 2023 and served breakfast tacos and coffee generously funded by my advisor (these were necessary to lure grad students away from their research). Only a few people showed up at first, most of whom thought artificial intelligence sounded interesting but weren’t seriously interested in making it the topic of their research. We continued to have meetings throughout the semester where professors would give chalk talks or we would try to figure out how AI worked, since none of us really knew at the time.

An early BioML Society meeting in Summer 2023.
We spent the summer building out the identity of the club. The best way to grow our base, we decided, was to educate others in the field so they could eventually join us. Aaron and I went to a whiteboard and drafted a syllabus of all that we had learned on this topic over the past year. His advisor, Claus Wilke, walked over, read it, and said that we needed to cut at least half of it since we’d sketched out easily two semesters’ worth of content. He also told us that with things like this, you never really know if it’ll have an impact or not beforehand, and that sometimes you just need to try something and see what happens. So we planned our reduced syllabus, realized it was still way too much work, and asked several other members of our club to teach a lecture. I would take the first one, then Aaron, Claus, Devansh, Aaron again, Devansh again, Daryl and Phillip, and then I would finish it off. I emailed several department heads to advertise the lecture series and promptly got yelled at by my advisor for spamming their emails. But it worked; we had over 80 people attend the first lecture. This dropped soon after, but it held steady at around 30 through the end. Every week the speaker would practice on Tuesday in front of the other organizers. Then on Wednesday we would steal our advisor’s microphone and camera, set up the lecture recording right before the UT campus-wide alarm test would sound at 11:45am, and then attempt to teach for an hour. We’d meet up afterwards to give office hours, debrief, and then I would upload the recordings to our YouTube channel. You can find the recordings here1.
It was hard to judge at first if this was a success or not. We certainly attracted people to the BioML Society and professors at UT generally reacted positively to it. A few months afterward, Claus informed Aaron and me that the associate dean wanted to talk to us about converting this lecture series into an official course to be taught by Claus. Fantastic! Claus went on to teach his expanded version of this lecture series in the falls of 2024 and 2025.
The semester after the lecture series, we continued to give chalk talks and host guest speakers. The repertoire gradually expanded to include some of the fantastic scientists whom I had met at NeurIPS a few months prior. On top of this, we were trying to figure out what would come next for the BioML Society. We had some research projects going within our club, but we wanted to engage the community again. One day we were brainstorming and somebody said, “We should do a protein design hackathon.” We all nodded our heads; it sounded like a great idea. AI models had only recently been applied to protein design, and their early successes convinced us that they would revolutionize how we design therapeutics in the future. But none of us even knew what a protein design hackathon would look like. Hackathons work well for coding challenges since you can verify the output of your code nearly instantly. Testing proteins, on the other hand, takes weeks and requires thousands of dollars’ worth of DNA, reagents, and equipment for only a relatively small number of samples. And so nodding our heads at the idea was all we did at that first meeting. This routine repeated itself over several more meetings, and each time we’d see the idea slightly more clearly.
One day a professor from the UT Austin medical school, Steve Ekker, showed up to a meeting, heard our hackathon planning routine, and told us that we should talk to a company called LEAH Labs. Their company was developing technology for chimeric antigen receptor (CAR)-T cell therapies to help cure cancer in dogs. This immunotherapy works by engineering T cells, which are immune cells that normally detect and eliminate cells infected with viruses, parasites, and so on. We can replace the receptor that lets them recognize infected cells with an engineered one that targets proteins on cancer cell surfaces, triggering the cancer cells’ destruction. CAR-T cells work well to cure certain cancers, specifically blood cancers like lymphomas.
One challenge in creating CAR-T therapies is finding a receptor that binds specifically to a target protein on the cancer cell. LEAH Labs had built a platform that screens candidate receptors in high throughput. They’d integrate thousands of designs at once into a population of T cells and then grow those cells either alone or alongside cancer cells expressing the target protein. Normally, when a T cell recognizes its target, it creates more copies of itself to better fight off the threat. LEAH’s platform exploits this behavior to estimate the efficacy of each design by quantifying how much more its T cells proliferated in the presence of cancer cells compared to the control.
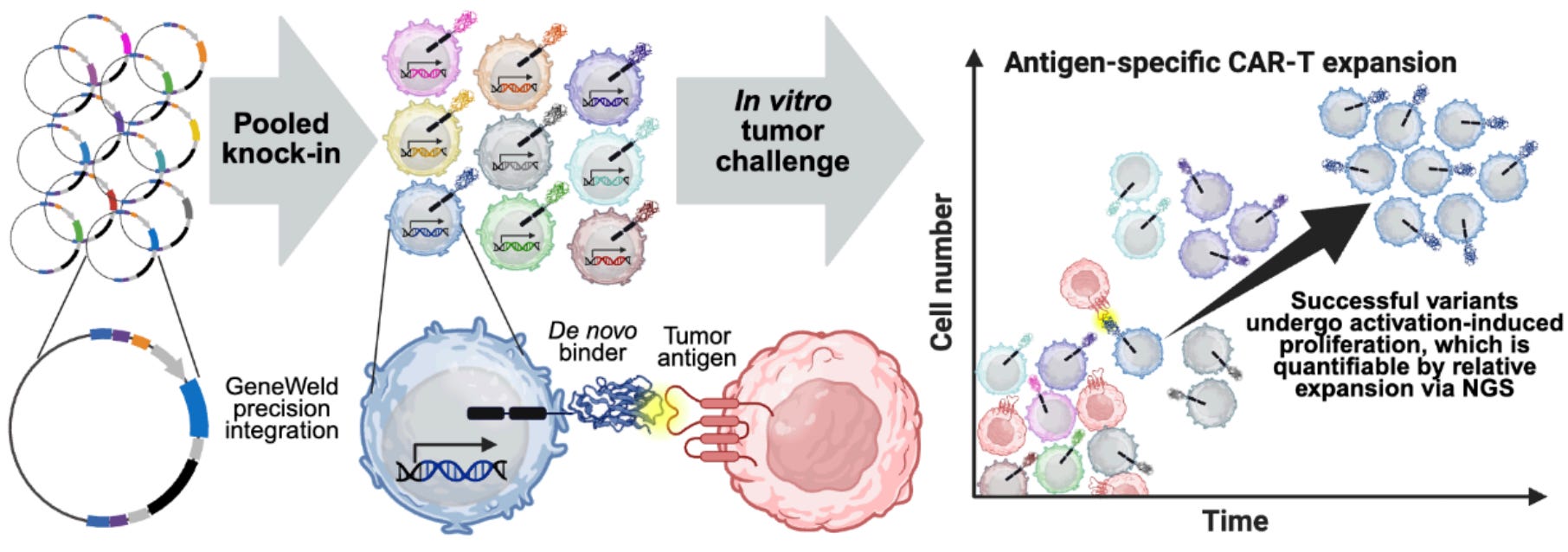
Diagram of how LEAH’s platform works, as detailed in our paper.
After learning about all of this, we realized that CAR-T design would be the perfect task for our hackathon. LEAH Labs had tried a round of this with the existing AI tools and found that they had a success rate of roughly 1/1000 in making working CARs. So the task was possible, but difficult. One of the notable factors in this task compared to existing protein design competitions was that this would not just measure protein binding, but would leap directly to evaluating whether generated proteins can elicit major functional responses in live human cells.
In late July, I was out in South Carolina visiting family when we announced the competition to the public. The social media algorithms apparently smiled down on us since our posts blew up in the biology and artificial intelligence research communities. Earlier, we said the event would be a success if just 10 people joined, and after only two days we were already at over 80 RSVPs! The next morning I received an email titled “Possible Nature news story on protein design contests”. A writer from Nature wanted to interview my collaborators and me about our competition! Over the next few weeks we had over 200 people from 42 countries enter. At this point we couldn’t actually believe this was happening. Here we were, a group of a few PhD students, who all of a sudden were running a worldwide protein design competition being covered by the top journal in science. This event was already a huge success. Now we just had to run the competition and deliver on what we promised.
In the weeks following the announcement, we secured enough money to test a total of 18,000 designs as a maximum, with 12,000 as a lower bound. This meant that all of the expected 60 teams could submit 300 designs each, though we’d ask teams for 500 just in case some people dropped out. With the money out of the way, we got ready for the kickoff event. This was to be a four-hour virtual event with many different speakers. The first half would introduce the task, the event, and the sponsors, and the second half was set for office hours to help answer questions about machine learning and biology. Wes from LEAH Labs flew out to Austin for the kickoff event and we met up on Saturday, August 24th, 2024, in the dimly lit room 3.204 in the Moffett Molecular Biology building. We got on the call, over a hundred people joined, and I started things off:
Protein design works, but nobody knows yet which methods and approaches work best. We are here today to figure out which methods work best. The target and task you will be working on... will be announced after these words from our sponsors.
Then I returned, revealed the task (designing proteins that help direct CAR-T cells to CD20-positive cancer cells), and passed it off to Wes to explain how the designs would be tested. I explained the submission procedure and revealed that the winners would get 3D-printed protein trophies as their awards. Phillip then walked through an example workflow, Aaron walked everyone through the provided compute options, and we ended by hosting office hours. Things ran much more smoothly than we expected; we only had one critical error in the design specs that was corrected immediately afterward over email. With that done, we cracked open some beers and went out for dinner and drinks downtown to celebrate. The competition was on.
After the six-week competition, 28 teams submitted designs. This was less than we had hoped, but given the difficulty of actually designing proteins, we were pretty happy that around half of the teams remained. In November, we submitted the designs for DNA synthesis, got the DNA at the end of January, and relayed it to LEAH Labs in Minnesota, who began testing a few weeks later. Preliminary results came back in April of 2025, the finalized high-throughput screen results in June, and validation of the top ten individual binders in August.

Sending the DNA for the 12,000 designs to LEAH Labs. This giant box contained just a few tiny vials of DNA packed in dry ice.
My collaborators and I couldn’t do anything for the competition during this time, so we turned our efforts elsewhere. Our PhD research continued. Aaron, Daryl, and I found internships in Boston and went away for the summer. During this time we worked with Texas Biologics and a private donor to establish a fully-funded BioML fellowship that supports two PhD students per year. But throughout the year, I had the unfinished competition gnawing away at me. I wanted more than anything to wrap it up and give the competitors and the general public their results.
We received the final experimental data from LEAH Labs in August. The results were better than we expected: 707 of the 12,000 designs worked in the high-throughput screen (compared to the roughly one in a thousand rate that we expected). Most of these successes came from only a handful of teams, one of which had 38% of their designs work. We also learned that some of the designs that worked in the proliferation screen functioned broadly as immunotherapies and could specifically neutralize the cancer cells. This meant that people from around the world, using open source AI-driven protein design tools, were able to design potential cancer therapies2.
Trophies given to the winners of the competition, each with their winning design in orange.
At this stage, I shifted to working full-time on analyzing the data. Since some teams had better success than others, it seemed possible that we could find general trends in the methods, or even the protein sequences themselves, that explained success or failure. Initially, Phillip and I started generating as many metrics for the proteins as we could. We were getting stuck and wanted a second opinion, so we brought in Jakub Lála, a competitor from one of the winning teams. Together, we generated over 400 different features, spanning every possible attribute of protein sequence and structure that we could think of. Early on, we noticed that the repetitiveness of the amino acid and DNA sequences was a moderate predictor of success. This didn’t make sense to us since we couldn’t think of a mechanism for why this would indicate success.
Eventually we realized that there were multiple distinct stages of success and failure in this task. We were considering only whether the detected designs increased or decreased cancer-specific proliferation. But the more interesting measurement was whether we detected the design after growing the cells, which indicated CAR-T cell viability. It turned out that our metric for how repetitive a DNA sequence was had an extraordinarily high ability to predict whether a design would produce a viable CAR-T cell. We then looked at the differences in DNA composition and found out that the high repetitiveness was well-explained by the codons used to encode amino acids. Lysine, for example, is coded by the nucleotides AAA and AAG. If there are multiple lysines in a row, the overall DNA repetitiveness is very high since the sequence is mostly A’s. We found existing literature suggesting a mechanism for why this caused poor cell viability: adenosine repeats can cause ribosomes to randomly stop creating proteins since the repeats resemble poly(A) tails. We did not experimentally confirm that this was the mechanism behind why many designs failed, but others have since found similar features causing failure in their proteins. You can read more about these findings in our preprint.
Beyond the science, the main thing that surprised me running Bits to Binders was the breadth of representation from the competitors. People entered from 42 countries spanning six of the seven continents. Some of these countries were actively at war with each other, yet the competitors were temporarily united by the common pursuit of scientific knowledge. It is hard to describe how surreal this was, especially since I never could have guessed how this event would play out. And honestly, I don’t think anyone could. This competition began from a chance idea at a BioML Society meeting. It required huge dedication from my collaborators, advisors, and friends. It required substantial funding and sponsorship from many companies. And above all, it required the efforts and ingenuity of dozens of teams around the world.
While writing this essay I felt some regret at not being able to keep up the momentum and excitement of the early days of the BioML Society. At the beginning we were riding the wave of the AI boom, getting introduced to new people each day, and really feeling like we were diving into something extraordinarily impactful. This tapered off starting around the end of 2024. We organizers—Aaron, Daryl, and I—got busy with our thesis projects and spent most of the remaining time we had trying to run and wrap up the competition. We then went away to Boston for summer internships, and thankfully Phillip stayed behind and did a great job keeping things going by running a reading group within BioML.
In many ways this lull was destined to happen. The projects we started grew almost past what a club of our scale could handle; starting another such project was completely out of the question. It’s possible that we could have avoided this by finding successors at the start of 2025, but nobody could step up then and so we floundered a bit. That period wasn’t all bad, though. We had some great guest speakers, including the co-founder of Recursion Pharmaceuticals and several other fantastic researchers and entrepreneurs.
Last fall a new cohort of graduate students arrived. We changed gears for BioML that fall and spent most of our meetings educating the new attendees about machine learning and how it can be applied to biology. This time around we were lucky to find several people in the room looking to make this thing their own. We’ve passed on the reins to Andy Basalla, Morgan Lane Handojo, and Logan Persyn, and I couldn’t be more excited about the future of the group.
Co-founding the BioML Society was easily the best decision I made in my PhD. It took far more time than I could have expected and often made me pursue projects that didn’t seem like normal science at first glance. But each time, the outcomes were greater than we expected. This group served as an engine that amplified our reach and ambition, allowing us to take on projects at a scale I never could have imagined in my first year of graduate school. My hope with the next generation is for them to think big and see where it goes.
Thanks to Daniel Winkler, Daniel Shea, and Aaron Feller for reading drafts of this and providing extensive feedback. And a big thank you to everyone who helped make Bits to Binders and BioML Society possible.
I don’t think the lectures aged very well; particularly since we learned all of the content a year beforehand and were far from experts. I brought this up to my advisor, Edward Marcotte, and he told me that this is the secret of teaching: every assistant professor learns the content as they teach the class.
Much more engineering and testing would need to be done for any of these to make it into humans. None of the designs outperformed the clinical positive control, but that is not surprising from zero-shot designs without feedback and iteration. What was surprising to us was that any of them worked at all, let alone at the rates we found.